Schnellere Laufzeiten durch Aktivierung von Parallel DML Operationen im ODI
Dieser erste Blogartikel der Artikelserie „Maßgeschneidertes & performantes ETL durch ODI Knowledge Modul Modifikationen“ setzt sich mit dem Einsatz von Parallel DML Operationen im ODI zur Performanceverbesserung auseinander. Hierbei ist die geschilderte Anpassung am ODI Knowledge Modul eher geringfügig, kann aber je nach Konstellation einen sehr großen positiven Impact auf die Laufzeit bieten. So wird im Laufe dieses Artikels exemplarisch anhand eines Beispiels gezeigt, wie die Laufzeit einer Insert-Into-Select Operation bei welcher über 135 Millionen Datensätze übertragen werden, von ursprünglichen 20 Minuten auf 3 Minuten durch die Optimierung reduziert werden konnte.
Parallelisierung
Die Nutzung von parallelen Operationen, stellt gerade bei großen Datenmengen, wie sie in Data Warehäusern häufig anzutreffen sind, eine sehr gute Möglichkeit zur Performanceverbesserung dar. Bei der parallelen Abarbeitung von Operation werden dabei mehrere Unterprozesse gestartet (oder PX (Parallel Execution) Server), die jeweils für sich eine Teilmenge der Daten bearbeiten und das Zwischenresultat dann zur Ermittlung des Endergebnisses an den zentralen Benutzerprozess (QC (Query Coordinator) Server oder PX Coordinator) zurückmelden. Hierdurch werden die zur Verfügung stehenden Rechnerressourcen besser ausgenutzt und eine zum Teil erhebliche Verbesserung der SQL Antwortzeiten bei Abfragen großer Tabellen erzielt.
Parallele Ausführung im ODI
Während bei ETL-Tools, wie z.B. IBM DataStage, die Transformationen von einem ETL-Server durchgeführt werden, und die Parallelisierung von Operationen damit diesem Server überlassen sind, verfolgen ELT-Tools, wie der Oracle Data Integrator, einen anderen Ansatz. Im ODI werden über ein Template-basiertes Verfahren SQL-Statements generiert und zur Ausführung an die Datenbank gesendet. Ob und zu welchem Grad diese Operationen parallelisiert ausgeführt werden, hängt dabei in erster Linie von der Datenbankkonfiguration, den betroffenen Datenbankobjekten und dem generierten SQL-Statement ab.
Die Templates zur SQL-Generierung liegen dabei in Form von sogenannten anpassbaren Knowledge Modulen vor. Der in den KM enthaltene Code entspricht dabei zu großen Teilen dem SQL, welcher anschließend generiert und auf der Datenbank ausgeführt wird. Nachfolgend ist beispielhaft ein solcher Vorlagencode eines relativ simplen Insert-Select KM-Schritts abgebildet:
<%if ( odiRef.getOption(„FLOW_CONTROL“).equals(„1“)) { %>
insert /*+ <%=odiRef.getOption(„HINT_INSERT_FLOW“)%> */ into <%=odiRef.getTable(„L“,“INT_NAME“,“A“)%>
(
<%=odiRef.getColList(„“, „[COL_NAME]“, „,nt“, „“,“((INS and !TRG) and REW)“)%>
)
<%for (int i=odiRef.getDataSetMin(); i <= odiRef.getDataSetMax(); i++){%>
<%=odiRef.getDataSet(i, „Operator“)%>
select <%=odiRef.getOption(„HINT_SELECT“)%>
<%=odiRef.getPop(„DISTINCT_ROWS“)%>
<%=odiRef.getColList(i,““, „[EXPRESSION]“, „,nt“, „“, „((INS and !TRG) and REW)“)%>
from <%=odiRef.getFrom(i)%>
…
Code 1: (Insert flow into I$ table – IKM Oracle Control Append)
Im Code befinden sich ODI-Substitutionsmethoden für Variablen (z.B. odiRef.getOption), mit denen die SQL-Statements über deklarative Regeln und Metadaten generisch erzeugt werden. Hier können neben den obligatorischen Tabellen- und Feldnamen z.B. auch optionale Optimizer Hints in das SQL eingefügt werden. Diese Hints werden über KM-Optionen im ODI gesetzt („HINT_INSERT_FLOW“, „HINT_INSERT_TARGET“, „HINT_SELECT“):
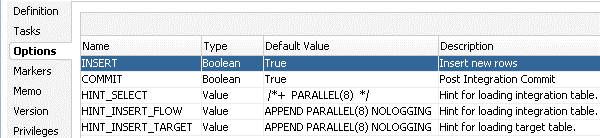
Abbildung 1: (Hint-Optionen in KM-Optionen)
In dieser Abbildung wurde die Option HINT_SELECT auf PARALLEL(8) und die beiden HINT_INSERT_X Optionen auf APPEND PARALLEL(8) NOLOGGING gesetzt. Es folgt ein beispielhaftes SQL, das auf Basis des Code 1 und den definierten Optimizer Hints aus Abbildung 1 entstehen könnte:
insert /*+ APPEND PARALLEL(8) NOLOGGING */
into DWH_ODI.CUSTOMER
(
CUSTOMER_ID,
DEPT_ID,
CUSTOMER_NAME
)
Select /*+ PARALLEL(8) */ *
from (
select /*+ PARALLEL(8) */
CUSTOMER.CUSTOMER_ID CUSTOMER_ID,
CUSTOMER.DEPT_ID DEPT_ID,
CUSTOMER.CUSTOMER_NAME CUSTOMER_NAME
from DWH_STAGE.CUSTOMER CUSTOMER
)
Code 2: (Erzeugtes SQL im KM-Schritt)
Bei Ausführung eines solchen SQLs auf einer Oracle 12C Datenbank (Version 12.0.2; weitestgehend Standard-Konfiguration) zeichnet sich bei Betrachtung der Sessions folgendes Bild ab:

Abbildung 3: (Blick in die Sessions (SQLDeveloper) auf den ausgeführten Befehl)
Zu sehen ist dabei, dass hier offensichtlich eine Parallelisierung stattfindet, weil für das Statement mehrere PX-Server aktiv sind.. Auch ein oberflächlicher Blick in den Ausführungsplan dieses Statements, scheint zu bestätigen, dass dieser Insert-Select Befehl parallelisiert ausgeführt wird:
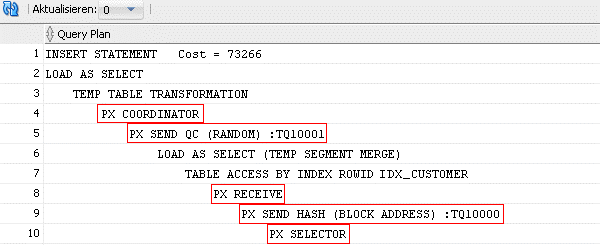
Abbildung 4: (Ausführungsplan Parallel Query Befehl)
Die Einträge PX COORDINATOR, PX SEND QC, PX RECEIVE, PX SEND HASH, PX SELECTOR zeigen eine parallele Bearbeitung auf. Zur Veranschaulichung der Laufzeit wurde im ODI der folgende Job ausgeführt:
In einem einfachen 1:1 Mapping, bestehend aus einer Quellview und einer Zieltabelle, wurden über 135 Millionen Datensätze von der Quelle in das Ziel übertragen. Das vom ODI generierte SQL entspricht dabei nahezu 1:1 dem betrachteten Insert-Select Statement, nebst den definierten Optimizer Hints aus Code 2. Unter Verwendung einer Oracle 12C Datenbank auf einem DB-Server mit 12 Cores, 192 GB Ram und einem Shared SAN-Filesystem, wies diese Operation dabei eine Laufzeit von 20:36 Minuten auf:
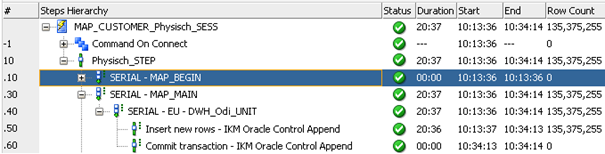
Abbildung 5: (Laufzeit Mapping 135 Millionen Datensätze)
Kann diese Laufzeit von 20:36 Minuten für die Übertragung der besagten 135 Millionen Datensätze noch verbessert werden, oder findet hier bereits eine vollständige & optimale Parallelisierung statt?
(Hinweis: Diese Frage richtet sich ausdrücklich nicht an den verwendeten Grad der Parallelisierung, was natürlich eine wichtige Rolle spielt. In diesem Beispiel wurde exemplarisch PARALLEL(8) verwendet. Oracle empfiehlt die Datenbank den Parallelitätsgrad bestimmen zu lassen (Auto DOP)).
Parallel Query != Parallel DML
Nicht ganz, denn in dem geschilderten Beispiel ist Parallel DML nicht aktiviert. Parallel DML steht für die parallele Ausführung von DML-Operationen wie Inserts, Updates und Deletes. Diese Option ist standardmäßig in Oracle 12C Datenbanken deaktiviert, wohingegen Parallel QUERY und Parallel DDL aktiviert sind. Auf welchem Wege lässt sich denn nun herausfinden ob Parallel DML aktiv ist oder nicht? Auf den ersten Blick war es zumindest in der SQLDeveloper Session Übersicht (Abbildung 3) nicht ersichtlich.
Ermitteln lässt sich diese Information aus der Spalte PDML_STATUS der View V$SESSION. Für das ausgeführte SQL aus unserem Beispiel erhalten wir unter Abfrage der View für die betroffene SID folgendes Ergebnis:
SELECT SID, USERNAME, PQ_STATUS, PDML_STATUS, PDDL_STATUS
FROM V$SESSIONS_PER_USER
WHERE SID = 3789;
(Code 3: SQL zur Abfrage von Parallel DML)
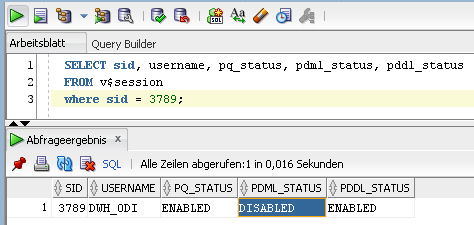
Abbildung 6: (Parallelisierung für den Befehl aktiv oder nicht?)
Hier wird dann auch ersichtlich, dass zwar Parallel Query (PQ_STATUS) und Parallel DDL (PDDL_STATUS) aktiviert sind, hingegen Parallel DML (PDML_STATUS) deaktiviert ist.
Impact von Parallel DML
Welchen konkreten Impact hat eine Aktivierung von Parallel DML auf das betrachtete Insert-Select Statement? Dies soll nachfolgend verdeutlicht werden.
Dazu wird im ersten Schritt Parallel DML für die Session aktiviert:
ALTER SESSION ENABLE PARALLEL DML;
(Code 4: PARALLEL DML aktivieren)
Eine Überprüfung mit dem Befehl aus Code 3 zeigt, dass PDML_STATUS hiernach nun aktiviert ist:
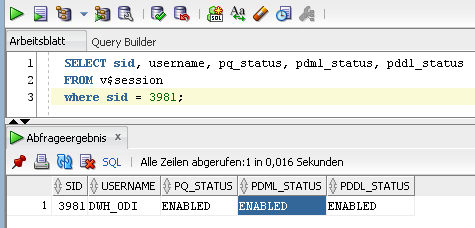
(Abbildung 7: Parallel DML abgefragt)
Jetzt wird das ODI-Mapping gestartet und damit das SQL auf der Datenbank ausgeführt. Ein Blick in die Sessions zeigt, dass weiterhin, wie erwartet, mehrere PX-Server für den Befehl aktiv sind – die SQL_ID ist im Vergleich zum obigen Lauf gleich geblieben (d.h. das Statement selbst ist absolut identisch):
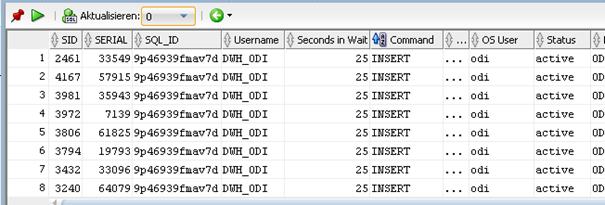
(Abbildung 8: Sessions für Parallel DML aktivierte Operation)
Bei Betrachtung des Ausführungsplans stellt man fest, dass dieser sich im Gegensatz zu dem Lauf mit deaktivierten Parallel DML geringfügig verändert hat:
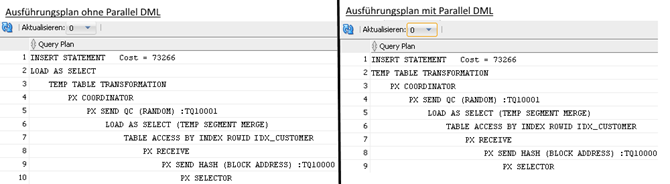
(Abbildung 9: Ausführungsplan Parallel DML -> Hier Screenshot mit Gegenüberstellung)
Der LOAD AS SELECT (=Direct Load Insert) Eintrag ist durch die Aktivierung von PARALLEL DML aus dem Ausführungsplan weggefallen.
Es folgt der Ausführungslog der Mapping-Ausführung aus dem ODI:
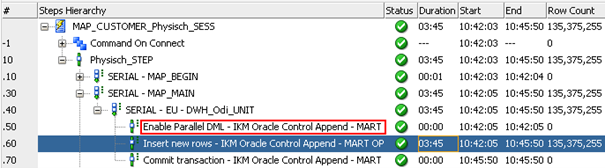
(Abbildung 10: Laufzeit mit Parallel DML)
Über den rot markierten Schritt mit dem Namen Enable Parallel DML wurde Parallel DML für die Datenbankoperation aktiviert. Im nachfolgenden Schritt sieht man in der Spalte Duration, dass die Operation mit aktiviertem Parallel DML lediglich 3:45 Minuten, statt den vorherigen 20:36 Minuten ohne Parallel DML gelaufen ist. Das entspricht also einer Laufzeitersparnis von annähernd 17 Minuten, die lediglich durch eine Aktivierung von Parallel DML zustande gekommen ist.
Wie Parallel DML generell und im ODI aktiviert wird, findet nachfolgend Betrachtung.
Aktivierung von Parallel DML im ODI
Für Oracle 12C Datenbanken kann Parallel DML für die jeweilige Session einfach über den Hint ENABLE_PARALLEL_DML aktiviert und mit DISABLE_PARALLEL_DML wieder deaktiviert werden. Im ODI geht die Aktivierung in diesem Fall erfreulich einfach von statten. Hierzu reicht es, in den Knowledge Modul Optionen, die Hint-Variable entsprechend zu setzen:

(Abbildung 11: Aktivierung von Parallel DML über Hints im ODI)
Das daraufhin vom ODI erzeugte SQL enthält dann den benötigten Hint zur Aktivierung von Parallel DML:
insert /*+ ENABLE_PARALLEL_DML */
into DWH_ODI.CUSTOMER
(
CUSTOMER_ID,
…..
(Code 5: Erzeugtes SQL mit dem Hint)
Leider funktioniert dieser Hint nicht auf Oracle 11g Datenbanken, wodurch hier eine geringfügige Modifikation an einer Kopie des jeweils verwendeten Integration Knowledge Moduls notwendig wird (z.B. Control Append, Slowly Changing Dimension 2, Incremental Update, etc.):
Hierzu sollte im aktuellen Projekt eine Projektkopie des gewünschten IKM’s eingefügt werden – in diesem Beispiel handelt es sich um das IKM Oracle Control Append:

(Abbildung 12: Lokale Kopie des IKM)
Es empfiehlt sich im Namen kenntlich zu machen, dass es sich hierbei um ein modifiziertes Knowledge Modul handelt (z.B. durch ein „CUSTOM“). Anschließend sollte das Knowledge Modul geöffnet und ein neuer Task hinzugefügt werden. Der Task sollte aussagekräftig benannt werden (z.B. Enable Parallel DML, ebenfalls mit einer Kennzeichnung wie „CUSTOM“ im Namen):
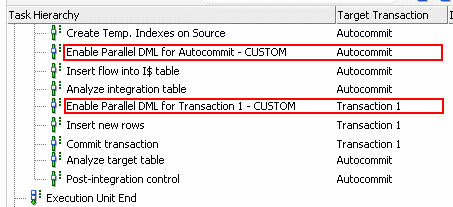
(Abbildung 13: Hinzugefügte Parallel DML Schritte im IKM)
Zu beachten gilt hierbei, dass Parallel DML pro Session aktiviert wird. D.h. wenn mehrere Transaktionen im Knowledge Modul verwendet werden und man für alle diese Transaktionen Parallel DML aktivieren möchte, so sollte ein entsprechender Aktivierungsschritt pro Transaktion eingefügt werden. So gibt es in dem obigen Beispiel die beiden Transaktionen Autocommit und Transaction 1 (Target Transaction). Die beiden kenntlich gemachten Aktivierungsschritte müssen mit folgendem ALTER SESSION Befehl erweitert werden:
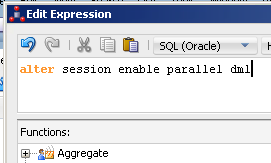
(Abbildung 14: Aktivierung von Parallel DML)
Wird im ODI dieses KM in einem Mapping ausgewählt und das entsprechende Mapping ausgeführt, so sollten die Operationen mit Parallel DML stattfinden. Zu beachten gilt hierbei, dass nach jeder Parallel DML Operation pro Session ein explizites Commit notwendig wird. Zur Überprüfung ob Parallel DML für die DML-Operationen vom ODI tatsächlich aktiviert ist, sollte sicherheitshalber eine Prüfung in der V$SESSION-View durchgeführt werden (Befehl siehe Code 3). Analog zu dieser Schilderung kann über einen gesonderten KM-Task Parallel DML mit dem Befehl „ALTER SESSION DISABLE PARALLEL DML“ wieder deaktiviert werden.
Zu beachten gilt, dass bei Parallel DML Operationen ein Overhead auftritt, das Transaktionsverhalten verändert wird und außerdem diverse Restriktionen vorhanden sind. Der Einsatz von Parallel DML ist damit also nicht pauschal sinnvoll und macht z.B. für OLTP-Anwendungen wenig Sinn. Mehr Informationen finden sich unter: https://docs.oracle.com/database/121/VLDBG/GUID-6626C70C-876C-47A4-8C01-9B66574062D8.htm#GUID-6626C70C-876C-47A4-8C01-9B66574062D8
Aber gerade im DWH-Kontext können wie in diesem Beispiel geschilderte DML-Operation durch den Einsatz von Parallel DML stark beschleunigt werden.
Quellen/Weiterführende Links Informationen
http://www.oracle.com/webfolder/technetwork/de/community/dbadmin/tipps/parallel_query/index.html